GPT 3 Demo and Explanation
Last week GPT3 was released by OpenAI and it’s nothing short of groundbreaking. It’s the largest leap in artificial intelligence we’ve seen in a long time and the implications of these advances will be felt for a really long time.
GPT 3 can write poetry, translate text, chat convincingly, and answer abstract questions. It’s being used to code, design, and much more.
I’m going to give you the basics and background of GPT3 and show you some of the amazing creations that have started to circle the Internet in just the first week of the technology being available to a limited set of developers.
Let’s start with a few examples of what’s possible.
Demonstration of GPT-3 designing user interface components:
GPT3 creating a simple react application:
Background
GTP3 comes from a company called OpenAI. OpenAI was founded by Elon Musk and Sam Altman (former president of Y-combinator the startup accelerator). OpenAI was founded with over a Billion invested to collaborate and create human-level AI for the benefit of the human race.
OpenAI has been developing it’s technology for a number of years. One of the early papers published was on Generative Pre-Training. The idea behind generative pre-training is that while most AI’s are trained on labeled data, there’s a ton of data that isn’t labeled. If you can evaluate the words and use them to train and tune the AI it can start to create predictions of future text on the unlabeled data. You repeat the process until predictions start to converge.
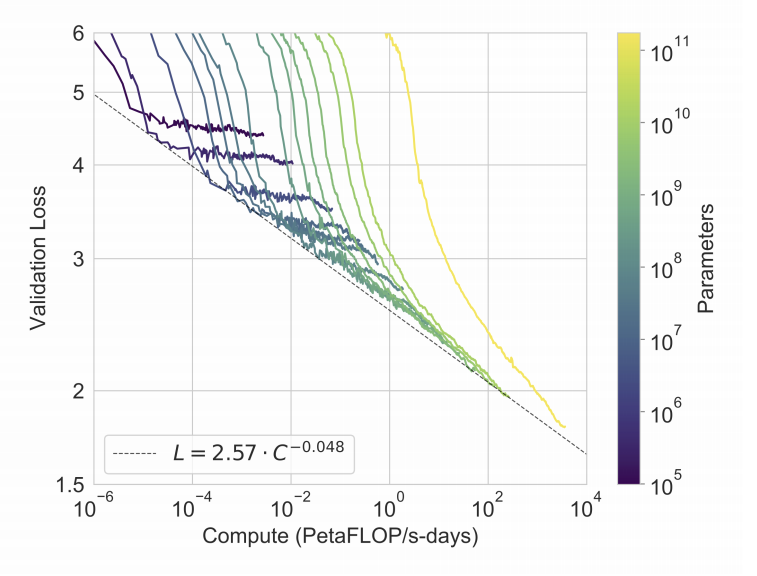
The original GPT stands for Generative Pre Training and the original GPT used 7000 books as the basis of training. The new GPT3 is trained on a lot more… In fact it’s trained on 410 billion tokens from crawling the Internet. 67 Billion from books. 3 Billion from Wikipedia and much more. In total it’s 175 Billion parameters and 570GB of filtered text (over 45 Terrabytes of unfiltered text)
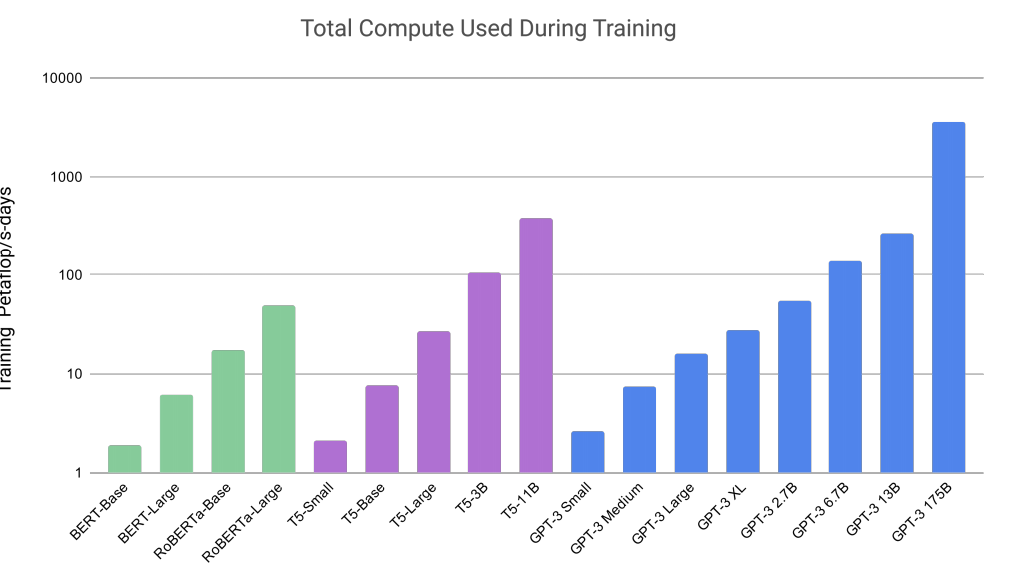
The amount of computing power that was used to pre-train the model is astounding. It’s over an exaflop day of computer power. One second of exaflop computer power would allow you to run a calculation per second for over 37 Trillion years.
The GPT3 technology is currently in limited Beta and early access developers are just starting to produce demonstrations of the technology. As the limited Beta expands you can expect to see a lot more interesting and deep applications of the technology. I believe it’ll shape the future of the Internet and how we use software and technology.
Links:
- Paper on GPT3 – Few Shot Learners https://arxiv.org/abs/2005.14165
- Beta Site for GPT 3 application developers
https://beta.openai.com/ - Original GPT paper
Archived Original Paper
- YouTube
Comments powered by Disqus.